Created on
Updated on
Virtual Production
a deep dive into the technical details

Preface: Welcome to this very long series of filmmaking in the age of AI(2026).
Facial Capture
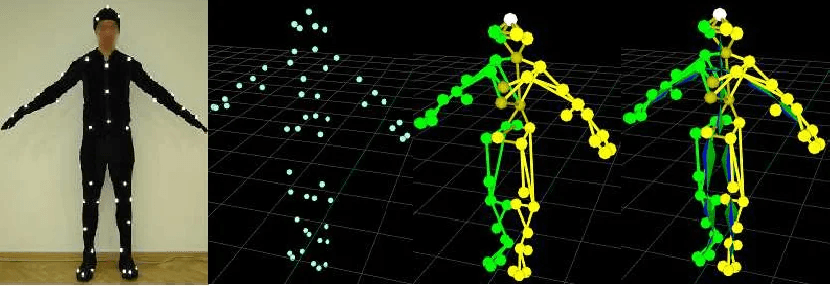
Body mocap captures the skeleton. For the Na'vi, whose emotional life needed to read in close-up with the same specificity as any human performance, body data alone was insufficient. Every actor in the performance capture sequences wore a head-mounted camera — a small rig attached to a helmet that positioned a camera approximately six inches in front of the actor's face, pointing directly at their facial surface. The actor's face was marked with a grid of small dots — not the large retroreflective markers used for body capture, but small painted reference points that the head-mounted camera could track against the facial surface. This facial reference data fed into Weta's facial pipeline alongside the body solve. The head-mounted camera footage was analyzed frame by frame, tracking the movement of the facial markers to produce a description of the actor's facial muscle activity — which parts of the face were contracting, by how much, in which directions, at every frame. Weta's facial rigging system, built on a FACS-compliant structure, received this data and drove corresponding movement in the Na'vi character's face. The combination of full-body optical mocap and simultaneous facial reference capture was what Cameron called the Imocap system — improved performance capture.

The Virtual Camera
A virtual camera is not a real camera. A virtual camera is a rigid body which shape and orientation and location is recognized and recorded in a configured / calibrated volume that's set up with OptiTrack / optical tracking system. Just like we mentioned previously, such cameras emit infrared, and these white markers are extremely reflective of these uv lights, while everywhere else has infrared light absorbed instead bounced back, the location of each white marker is easily identified when calculating the light received on each infrared camera / OptiTrack / Optical tracking system camera.
Since OptiTrack cameras have a ring of infrared LEDs built directly around the lens, and these LEDs pulse in sync with the camera's shutter — they fire a burst of near-infrared light at the same instant the camera exposes. The markers on the suit are retroreflective, meaning they return light directly back toward its source rather than scattering it in all directions. Road signs work the same way — they're covered in tiny glass beads or prismatic material that bounces your headlights straight back at you regardless of angle. The camera lens has an infrared bandpass filter on it. This filter blocks visible light entirely and only lets through the specific infrared wavelength the LEDs emit — typically around 850nm or 940nm, which sits just outside what the human eye can see. From the camera's perspective, the entire world goes black. The only things that register are the markers, which appear as intensely bright white points against a pure black field.This is why the volume's lighting doesn't matter. The stage can be lit however it needs to be for reference cameras and crew visibility. The mocap cameras don't see any of it. They see only the markers.
Rigid body literally means rigid body as defined in physics books: "A rigid body is an idealized solid object in classical mechanics that does not deform, flex, or change shape, meaning the distance between any two points on it remains constant, regardless of forces applied. It is defined by 6 degrees of freedom (3 translational, 3 rotational) and is used to analyze translation, rotation, and complex motion. "
Here, the rigid body we use is just a block with tentacles with retroreflective markers on ir ends. This is where the camera is in the volume, but since the volume is fully CG, the camera doesn't have to be a real camera with a real lens, since it doesn't need to "see" the real world, it only needs to "see" the CG world, "if" at this location, there's a lens pointing this direction. Does that make sense?

So you wave the virtual camera, which is just a marked rigid body, the image is fed to a monitor, and you can see what the lens would see if this CG environment was real, and if this virtual camera was really this lens pointing at this direction. Unless you need to composite CG environment with practical environment in real time, you can just use this rigid body as a virtual camera. But if you need to composite practical and virtual in real time, you gotta attach it to a real camera, have the camera's image and virtual camera's image combine in real time.

What will add another layer of complexity to this, is when you want to add a motion captured character, aka someone wearing a screen suit with markers attached all over like this:

Because now you need to composite this on top of virtual camera's feed, real camera's feed. This processing system is a chain of five distinct systems, each feeding the next, all running simultaneously at a speed that kept the total latency below what a human brain registers as delay. Break it down step by step.
The same optical mocap units that tracked the performers' body markers also tracked the virtual camera rig. Retroreflective markers were attached to the rig at known positions. The markers relationship to each other solves their position in three-dimensional space at every frame — the same triangulation process used for the actors, applied to a physical object rather than a person. This gave the system a continuous, precise description of where the virtual camera was in the volume, how it was oriented, and how it was moving, updated in real time. Alongside the positional tracking, the Overdrive system developed by Concept Overdrive (https://conceptoverdrive.com/products/control_sys.php) pulled lens data from Vince Pace (Cinematographer)'s camera hardware — focus, iris, zoom, interocular and convergence in real-time — and used that information to come up with a camera solve, knowing where it was in 3D space.
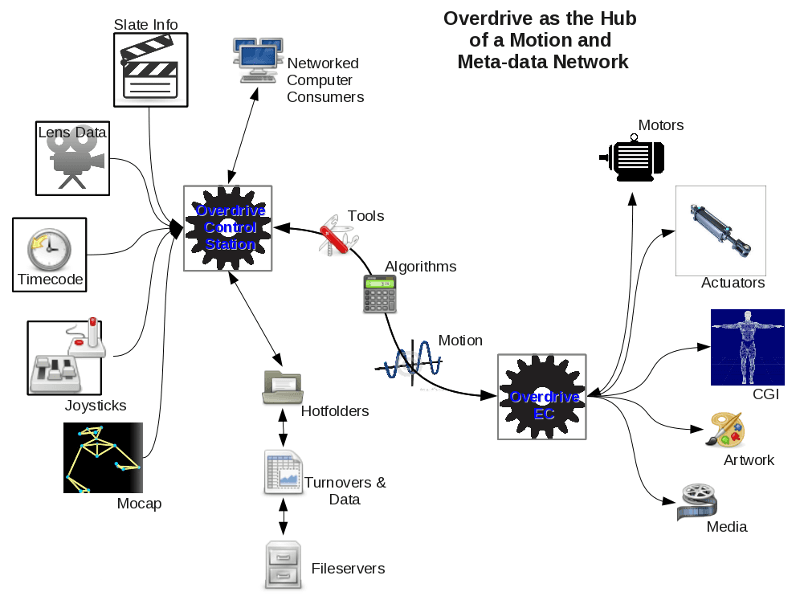
Simultaneously, the mocap system was processing the actors' marker data into skeleton solves. They solved the characters in real time, solving for a skeleton and retargeting to the CG character, as we mentioned in the mocap post. The retargeting happened immediately — the human performer's joint angles and velocities translated into the Na'vi character's skeleton in the same processing pass. The real-time solve was approximate — good enough to evaluate performance, not good enough to animate from directly without cleanup.
Both data streams — the camera solve and the character solves — fed into Autodesk MotionBuilder, which was the hub of the real-time pipeline. They streamed into MotionBuilder, which is the industry-standard viewing tool, live on set. MotionBuilder crashed all the time. MotionBuilder received the incoming data streams and maintained a live scene: Na'vi characters moving through a virtual environment, seen from a camera that matched the position and lens properties of the physical rig Cameron was holding.
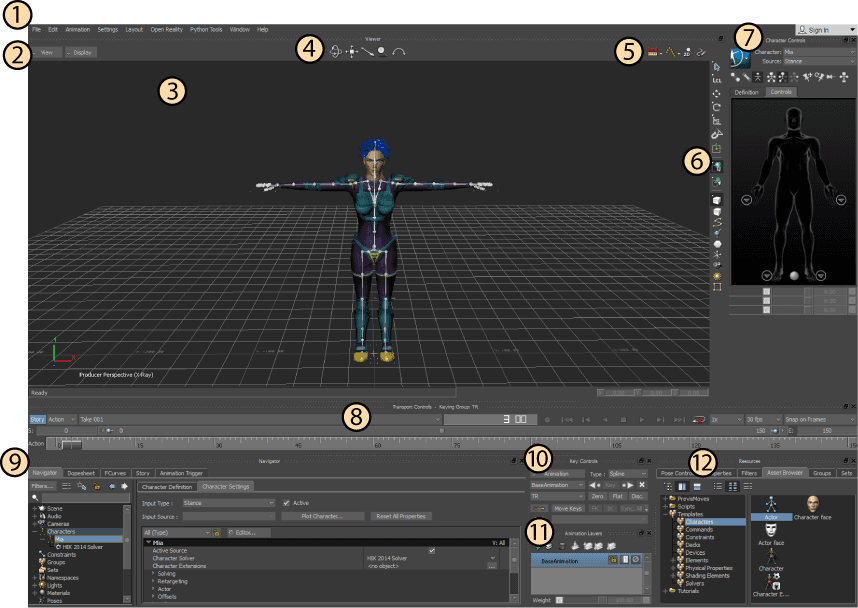
What Cameron saw in the viewfinder wasn't Weta's final-quality Pandora. It couldn't be — rendering Weta's final environments in real time was computationally impossible in 2009. What he saw was a purpose-built real-time version of the environments, constructed specifically for the virtual production phase. LightWave created all of the assets for the real-time virtual sets and MotionBuilder was used because it has a more robust real-time OpenGL engine.

Then, once everything was nailed down, the virtual sets were rezzed up or rebuilt in ZBrush and Maya and rendered from there. LightWave was the main workhorse to build the virtual sets mainly because they had a ton of assets that had to be created daily based on concept designs given by the concept artists. The fast workflow enabled them to keep up with the massive workload. Much of what was created in 3D was inspected by James Cameron himself and approved and put into the sets under his direction. So there were effectively two versions of every environment on Pandora running in parallel: the real-time OpenGL version that Cameron worked with during the virtual production phase, and the fully rendered Weta version that became the final film. The real-time version existed to serve the director's creative process. The final version existed to serve the audience.
Cameron's virtual camera system allowed him to direct the performance capture sequences as a cinematographer rather than as an overseer watching data. While the actors performed in the volume, Cameron moved through the same space holding a camera-shaped device whose position and orientation were tracked by the mocap array. A separate processing system took the camera tracking data and the actor performance data and rendered a real-time preview of the Na'vi characters moving through a rough version of the Pandoran environment from the perspective of Cameron's virtual camera. This process is worth discussing, despite its complexity. Cameron looked at a monitor showing not the actors in the volume but the Na'vi on Pandora, seen from exactly the angle he was physically pointing the virtual camera. He could push in on a performance, pull back to reframe, circle an actor during a dramatic moment — all the instinctive physical language of cinematography applied to a world that didn't physically exist. When he saw a moment he wanted to capture, he called action. When the framing wasn't working, he moved. The virtual camera gave Cameron's directorial instincts direct access to the digital world in a way that no previous technology had provided.
This was significant beyond the technical achievement. It meant that the camera language of Avatar — the coverage choices, the framing decisions, the physical relationship between camera and performance — came from a director operating intuitively with his hands on the camera rather than from a technical team making decisions at a workstation in a review session. The performances were directed by someone who was, in the most literal sense, in the scene with the actors. Virtual production is the most significant shift in how VFX films get made since the introduction of digital compositing. The traditional green screen model separates the world. Actors perform in front of a blank colored surface. The environment they're supposed to be in gets built in post, weeks or months later, by artists who weren't on set. The director makes decisions about performances without being able to see how those performances will relate to the final environment. The actors perform without seeing the world their characters inhabit. The lighting on the actors, designed to match an environment that doesn't exist yet, gets finessed in compositing. The final image is an assembly of separately captured components.
🫶🏼