Created on
Updated on
Motion Capture
we need to discuss MoCap before we can make sense of Virtual Production

Preface: Welcome to this very long series of filmmaking in the age of AI(2026).
The earliest motion capture systems used magnetic sensors attached to the performer's body, tracking their position relative to a transmitter in the capture space. The data was crude by current standards, but the principle was established: attach tracking points to a human, record where those points go, and you have a description of human movement that can drive anything. Modern optical motion capture — the dominant approach on large productions — uses retroreflective markers attached to a form-fitting suit at every significant joint and body landmark: shoulders, elbows, wrists, hips, knees, ankles, spine, and head. The capture volume — the space in which the performance happens — is surrounded by cameras that emit infrared light. The markers reflect that light back to the cameras, which track their position in three-dimensional space at high frame rates, typically 120 frames per second or higher. Software assembles the positional data from all the cameras into a three-dimensional point cloud that describes the performer's skeleton at every frame.

That raw data is called the solve. A clean solve means every marker was visible to enough cameras at every frame, producing a complete and accurate description of the movement. A dirty solve — caused by markers occluding each other during complex movements, or by the performer leaving the range of certain cameras, or by reflective surfaces in the environment confusing the system — produces gaps and errors that have to be cleaned by hand. Data cleaning is meticulous work: motion editors go through the capture data frame by frame, identifying and correcting errors, filling gaps, smoothing jitter, until the solve accurately represents what the performer did.
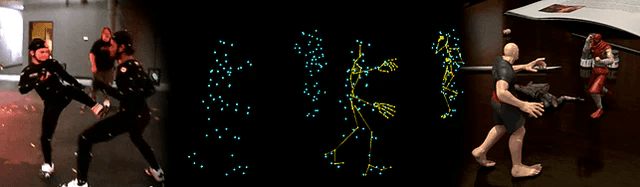
The cleaned data then gets retargeted — mapped from the performer's body onto the proportions of the digital character. A performer who is five feet ten inches drives a character who might be eight feet tall or three feet wide. The retargeting system maps the relationships between joints — the relative angles and velocities — rather than the absolute positions, so the character moves with the performer's timing and quality even though the proportions are completely different. How well retargeting works depends on how well the character's rig was built to receive the data and how compatible the movement qualities of the performer and the character are.

The conversation about whether performance capture acting deserves the same recognition as conventional screen acting is unresolved and worth having. The camera doesn't record the actor's face. The audience never sees their performance directly. But the movement, the timing, the emotional choices — these are the actor's. The debate says more about how we think about acting as a discipline than it does about whether the work is real.
Inertial Mocap
Anyways, inertial motion capture meant basically gyroscope motion capture. You put on this strange-looking suit, with a few gyroscopes hidden in different spots. Each gyroscope records its movement, and through some software computation that i'm not sure the details of, it can record the movement of the human body. This is how Claude explains it, actually better than I did: an inertial motion capture suit is fitted with IMUs — inertial measurement units — at every major body segment. Each IMU contains three instruments working simultaneously: an accelerometer, which measures linear acceleration in three axes; a gyroscope, which measures rotational velocity around three axes; and a magnetometer, which measures orientation relative to the Earth's magnetic field.
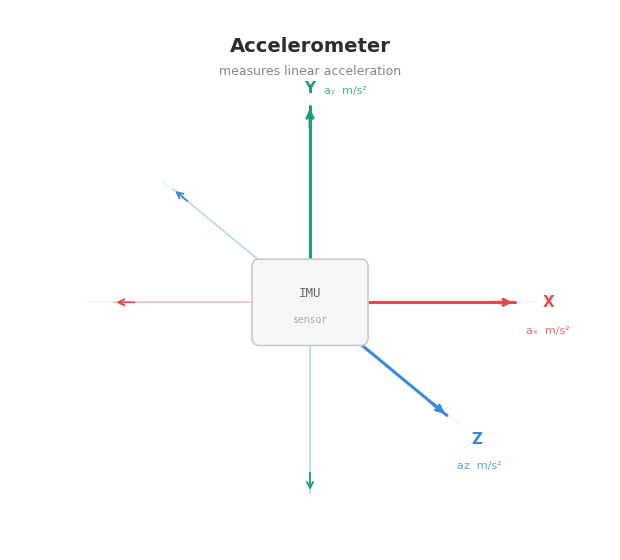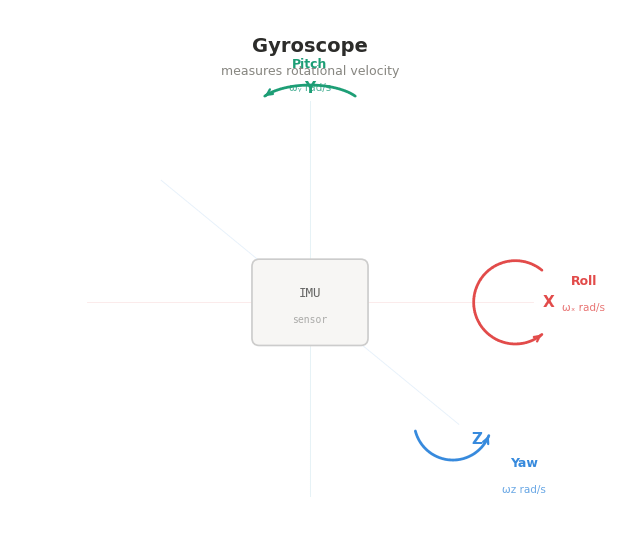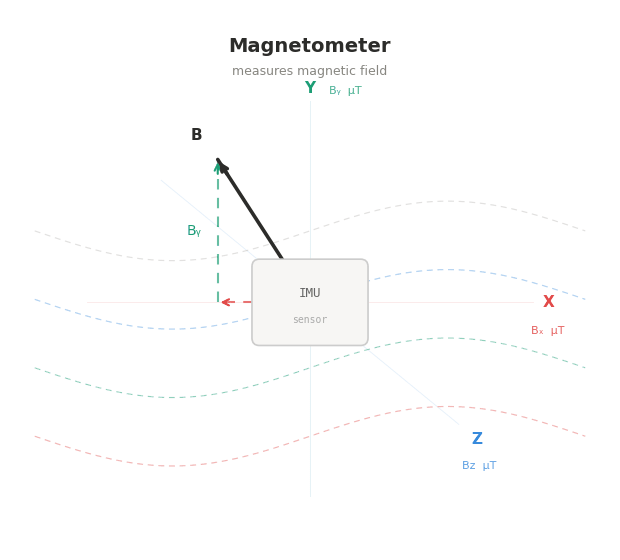
Together these three sensors give each unit a continuous, real-time description of exactly how that body segment is accelerating, rotating, and orienting itself in space at every moment.

The data from all the IMUs on the suit gets processed together to reconstruct the full body skeleton. If the hip segment rotates forward and the thigh segment rotates backward at a specific rate, the system calculates that the performer is bending at the hip. The relationships between adjacent segments — their relative angles, velocities, and accelerations — describe the movement of the skeleton without needing any external reference point to observe it. This is the fundamental difference from optical mocap, which I'll explain in just a sec. Optical tracking knows where markers are in absolute three-dimensional space because the camera array provides an external reference. Inertial tracking knows how body segments are moving relative to each other, but derives absolute position by integrating acceleration over time — mathematically summing up all the small movements to estimate where the body has traveled from its starting point. Basically, inertial MoCap only record the relative movements, without associated with a 3-dimensional coordinate reference system. We know how it moves, but we don't know where it is in relation to our space.
Every time you integrate a measurement, you integrate the error in that measurement along with the data. A tiny inaccuracy in an accelerometer reading — smaller than any practical calibration can eliminate — accumulates over time. After a few seconds of movement, the estimated position has drifted slightly from the real position. After a minute, the drift is visible. After several minutes, the character's position in the data may have traveled several feet from where the performer actually is. This means inertial mocap data is reliable for relative movement — the quality of a walk cycle, the timing of a gesture, the dynamics of a fight sequence — and progressively less reliable for absolute position over extended capture sessions. Productions that use inertial mocap manage drift by periodically resetting the performer's position — returning to a known reference point, or using hybrid systems that anchor the inertial data to absolute position measurements from GPS outdoors or ultra-wide-band positioning indoors.
The magnetometer, which helps anchor orientation to magnetic north, introduces its own problem in indoor environments. Metal structures, electrical cables, motors, and other magnetic field sources distort the local magnetic environment and corrupt the magnetometer readings. Many indoor stages are magnetically hostile enough that the magnetometer has to be disabled or down-weighted, reducing the system's ability to correct rotational drift. The Xsens system — the dominant professional inertial mocap platform in film and VFX production — handles this through sensor fusion algorithms that weight each input based on its current reliability, but the fundamental susceptibility to magnetic interference remains.
Despite its limitations, inertial mocap enables things optical mocap cannot. The performer can go anywhere — outdoors, across a large set, through practical environments, on location. A director who needs to capture the movement of a character running through a real forest, climbing a real structure, or moving through a space too large to ring with cameras has a tool that optical mocap simply cannot provide. Setup is fast. An optical volume takes hours to calibrate. An inertial suit takes minutes to put on and initialize. For productions that need to capture a large number of sessions across varied locations, or that need to capture mocap data on a tight schedule without the overhead of a permanent stage, inertial systems compress the time cost of capture dramatically. The systems are portable and relatively affordable. Professional optical mocap infrastructure — camera arrays, processing hardware, software licenses — represents a capital investment that limits access to well-funded productions and dedicated facilities. High-end inertial systems like Xsens are expensive but within reach of mid-budget productions and independent studios. Lower-cost systems like Rokoko and Perception Neuron have brought inertial mocap to a price point accessible to individual artists, small studios, and game developers. The democratization of motion capture as a production tool is largely a consequence of inertial technology.
In film and VFX production, inertial mocap is most commonly used in combination with optical rather than as a replacement for it. Hero sequences — close-up performance work where the data quality needs to be highest and drift is unacceptable — go through the optical pipeline on a controlled stage. Secondary character work, background crowd data, reference capture on location, and any capture that needs to happen outside the confines of the optical volume uses inertial. The two data streams can be processed together. An actor's primary performance might be captured optically, while their broad movement through a large physical space — a walk across a field, a chase through a building — gets supplemented with inertial data that extends the capture beyond the volume's limits. The pipeline merges them, using the optical data's precision where it exists and the inertial data's spatial freedom where it doesn't.
Optical MoCap
Optical motion capture is the dominant system for hero performance work in film production because it offers something inertial systems cannot: absolute positional accuracy in three-dimensional space, at every frame, with submillimeter precision. The infrastructure required to achieve that accuracy is substantial, but for sequences where the quality of the captured performance is the foundation on which everything else gets built, no alternative delivers comparable results.

The optical mocap stage is called the volume — the defined three-dimensional space within which capture is accurate. The volume is enclosed by a precisely positioned array of cameras, typically ranging from dozens to hundreds depending on the size and complexity of the capture space. These are not standard video cameras. They are high-speed infrared cameras capable of running at 120 to 240 frames per second, each equipped with an infrared strobe ring that pulses light at the same frequency as the shutter. Back in the days, we used this company's product called OptiTrack(https://optitrack.com/cameras), still alive today. The cameras see only infrared light. The physical environment of the stage — walls, floors, crew, equipment — is invisible to them. What they see are the retroreflective markers on the performer, which return the infrared strobe light directly back to the cameras with high efficiency, appearing as bright points of light against a black field.



Before any capture session, the volume gets calibrated. A technician moves through the space waving a calibration wand — a rigid object with markers at precisely known positions — while the camera array records its movement.

Software analyzes the wand data across all cameras simultaneously and solves the exact position and orientation of every camera in the array relative to every other camera. This calibration is what allows the system to triangulate — using the same marker visible from multiple cameras at slightly different angles to calculate its precise position in three-dimensional space. A well-calibrated volume is accurate to fractions of a millimeter. A poorly calibrated one produces data that drifts and errors that cascade through every downstream process.
You can record what we call rigid bodies, or people movement and various other things. This is way more accurate than inertial MoCap, since it's configured in a set space, and we can know the absolute position the configured shape is at any given time within the volume. This technology, along with FACS, facial capture, are what made James Cameron's Avatar(2009) possible.

James Cameron's Avatar(2009)
James Cameron had conceived Avatar in the mid-1990s and shelved it because the technology to make it didn't exist. The Na'vi were not going to be achieved with practical creatures. They required digital characters whose performances originated in human actors — fully, completely, in every detail of expression and movement — rendered at a quality level that the audience would accept as photographic reality. Cameron waited until he believed the technology could deliver that, and then he built the infrastructure to prove it.

The performance capture volume built for Avatar at Manhattan Beach Studios was one of the largest and most technically sophisticated ever constructed for a film production.

The stage enclosed a capture space large enough for multiple actors to perform simultaneously — to be physically present with each other, to make genuine eye contact, to move through the scene together as a cast rather than performing in isolation and having their data assembled in post. Let's dive into virtual production next.
🫶🏼