Created on
Updated on
The Society of Silicon: Why the GPU is the First Truly Biological Machine
From Denny’s to Deep Learning: Navigating the "Strong Emergence" of consciousness in a world of parallel math.

Preface: First Principle thinking, and Minsky’s second book that inspired Jensen Huang to create GPUs. Co-written with Gemini.
When Minsky proposed the two impossibles in solving artificial intelligence in his first book, Perceptron, in 1958, he didn’t know how to solve them. He knew that the hardware infrastructure at the time was impossible to carry the complex calculations we’d need, and he didn’t know how to teach an algorithm to a machine. When Minsky's second book, The Society of Mind, was published in 1987, Jensen was completing his Master’s in Electrical Engineering at Stanford University (graduated 1992). This was a period when Minsky’s theories were being heavily debated in academic circles. Jensen has often discussed how "First Principles" thinking—a cornerstone of Stanford’s engineering culture—led him to look at computation through a biological and modular lens. We hear the phrase “First Principles” tossed around a lot, but essentially it’s the act of boiling a problem down to its most fundamental, indisputable truths and building a solution from the ground up, rather than relying on how things were done in the past. It is often contrasted with "Reasoning by Analogy," which is how most of us think. Analogy says, "We should do X because it's like Y, and Y worked." First Principles says, "Forget Y. What are the physical laws and basic facts we are working with here?"
To think from first principles, you generally follow this loop. List everything you think you know about the problem (e.g., "Rockets are expensive because they’ve always been $60M"), then strip away the "baggage" until you hit the "atomic" facts (e.g., "What is a rocket actually made of? Aluminum, titanium, and fuel. What do those raw materials cost on the market?"), lastly use those raw facts to build a new path (e.g., "If the materials only cost $2M, how can we combine them more efficiently to build a cheaper rocket?"). Most people don't use first principles because it is mentally exhausting. Analogy is a shortcut; it saves energy by letting us copy existing patterns. First Principles requires you to "doubt everything" (a method famously used by René Descartes) until you find something you can't doubt anymore. When NVIDIA started, the standard was to build CPUs to handle everything. Jensen went back to first principles: "What does graphics math actually require?" He realized it wasn't one complex "genius" logic gate, but millions of tiny, simple "addition" steps. He didn't build a better CPU; he built an entirely different "machine" (the GPU). When Jensen, Chris Malachowsky, and Curtis Priem met at Denny's in 1993, they didn't ask, "How do we make a better graphics card?" They asked: "What is the most difficult problem in computing that people will pay to solve?" The team broke 3D graphics down to its atomic level. They realized that a 3D image isn't a "picture"—it's a massive collection of triangles and pixels. The traditional CPU is one powerful processor that does everything. It calculates where a triangle is, then how light hits it, then what color it should be, one after another. Because every pixel’s color is independent of the others, you don't need a "genius" processor; you need a "society of simple workers" working in parallel.
In the early 90s, the CPU was the "boss" of the computer. It did all the thinking and just sent the final results to the graphics card to be displayed. The "wire" (bus) between the CPU and the graphics card was too slow. As games got more complex, the CPU couldn't keep up. At the most basic level, a computer chip does math using an ALU (Arithmetic Logic Unit). A CPU has a few, very large, very complex ALUs. They are "Generalists." They can add, subtract, predict which way a program will branch, and handle "if/then" logic at 5.0 GHz. They realized that to draw a 3D world, you don't need "if/then" logic; you just need to multiply and add numbers over and over (Matrix Math). This is the fundamental "fork in the road" between the two most important types of chips in history. To understand it, we have to look at why "if/then" logic is the enemy of speed, and why Matrix Math is the secret to reality.
A CPU is designed to handle unpredictable tasks. When you use Excel, browse the web, or run an OS, the computer is constantly making decisions:"If the user clicks this button, then open this menu; else, stay idle.", or"If the password matches, then grant access." To do this at 5.0 GHz, which is 5 billion times per second, the CPU uses a massive amount of its "brain power" on Branch Prediction. It literally tries to guess the future. It guesses which way an "if" statement will go and starts working on it before you even click. If it guesses wrong, it has to throw away all that work and start over. This makes the CPU a "genius," but a very lonely one—it spends most of its time managing its own thoughts.
When you render a 3D world (or train an AI), there are almost no "if" statements. You don't ask, "If this pixel is red..." You say, "Multiply these 1 million light values by these 1 million surface colors." This is Matrix Math. In physics and graphics, almost everything is a "Dot Product"—a fancy way of saying "multiply a bunch of pairs and add them up."
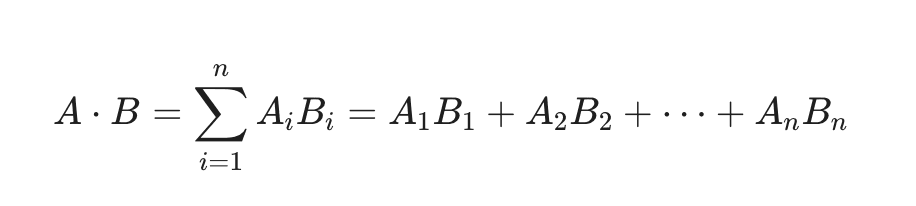
A CPU is built to be a high-performance soloist. To make sure it never stops working, it uses massive amounts of silicon for Branch Prediction, which is a giant "guessing engine" that tries to predict which way your code will turn (if/else). It also uses Deep Caches, which are massive pools of memory built right into the chip to store data "just in case" the CPU needs it. And then there is the Out-of-Order Execution Logic, which is a complex circuitry that re-arranges your code on the fly to find parts that can be done faster. You can see how in this setup, a lot of the calculation power is used to predict, and calculate in advance, and stored in caches, just in case it’s needed, and when it’s not, that information is tossed away. In a typical CPU, only about 10% to 20% of the actual chip surface is dedicated to the ALU (the part that actually does the math). The rest is just "the manager" making sure that one ALU is always busy.
NVIDIA’s "First Principles" realization was that for graphics, stalls don't matter. If one pixel takes a millisecond longer than another, the user won't notice, as long as all 8 million pixels show up on time. Because they didn't care about "latency" (speed of a single task), they could strip away the Branch PredictionI, since the GPU assumes every thread is doing the same thing. Instead of huge internal memory, they built a massive "highway" (high bandwidth) to external memory, and Deep Caches are therefore replaced by tiny caches. Instead of having Out-of-Order Execution Logic that re-arranges the code on the fly to find parts that can be done faster, GPUs use simple control logic, which allows one "manager" to handle a group of 32 or more ALUs. By removing the "Management Tax," NVIDIA could fit thousands of ALUs in the same square millimeter where a CPU could only fit a few. They stripped away the "smart" parts of the ALU and made them as small as possible so they could cram thousands of them onto one piece of silicon. This was the transition from Serial Processing to Parallel Processing. In Serial Processing, the chip solves problem A, then problem B, then problem C. If you have 1,000 pixels to color, the CPU does them one by one. Even if it's very fast, it’s still a "queue." However, the Massively Parallel (The NVIDIA Way) has the GPU takes all 1,000 pixels and hands one pixel to each of its 1,000 tiny cores. They all "fire" at the exact same time. The task is finished in the time it takes to do one calculation, rather than one thousand.
And this concept of Parallel Processing was from Minsky’s second book, The Society of Mind. In The Society of Mind (1986), Marvin Minsky argues that the human mind is not a single, unified "thing," but a vast society of tiny, mindless processes called agents. His core question is: How can intelligence emerge from non-intelligence? His answer is that while each individual agent is simple and "dumb" (capable of only one specific, tiny task), when they are joined together in specific organizational structures, they produce the complex behaviors we call "thinking," "feeling," and "consciousness." This is from the concept of Emergence. Emergence is the phenomenon where a complex system exhibits properties that none of its individual parts possess. It is the scientific version of the phrase: "The whole is greater than the sum of its parts." A classic example is The Ant Colony. An individual ant is "dumb." It has a tiny brain, limited senses, and a very simple set of rules (e.g., "If you find food, leave a scent trail"). However, when putting together millions of simple ants, the Emergence is an Ant Colony. The colony as a whole acts like a "super-organism." It can solve complex geometry, bridge gaps, farm fungus, and wage war. No single ant "understands" the blueprint of the nest, yet the nest gets built. The wetness of water is another classic example of Emergence. Hydrogen and Oxygen atoms. Neither of these gases is "wet." When you combine them into H2O at the right temperature, "wetness" emerges. You cannot find the "wet" property by looking at a single molecule; it only exists when trillions of them interact. This is exactly how ChatGPT and other Large Language Models (LLMs) work. Billions of simple mathematical "weights" on an NVIDIA GPU (the agents). Each weight just does a simple "multiply and add" calculation (the task). Developers did not "program" the AI to understand sarcasm or how to write code. They simply built a massive "society" of math agents, and as the system got larger, these complex abilities emerged spontaneously. Philosophers like Daniel Dennett often distinguish between two types. For a Weak Emergence, we can see how the parts create the whole, even if it's complex (e.g., a car engine's power comes from thousands of explosions). For a Strong Emergence, the new property is so different from the parts that it’s almost impossible to explain how it happened (e.g., how "meat" in the brain creates the "feeling" of love or consciousness). In the context of Marvin Minsky’s Society of Mind and NVIDIA’s AI, emergence is the "magic" that happens when you connect enough simple "agents" together.
Minsky breaks the mind down into a hierarchy. These are the smallest units of thought. An agent might be responsible for "seeing a red color," "moving a finger," or "recognizing a vertical line." By itself, an agent has no "mind." When agents work together to accomplish a larger task, they form an agency. For example, a "Builder" agency might consist of separate agents for "Find a block," "Pick up a block," and "Add it to the tower." Minsky introduces the concept of K-lines (Knowledge-lines) to explain memory. A K-line is essentially a mental "wire" that, when activated, turns on a specific group of agents that were active when you learned something or solved a problem in the past. Instead of storing "data" like a hard drive, the mind stores configurations. Memory is the act of re-activating a previous "state" of your mental society. To explain how we handle new situations, Minsky uses Frames. A frame is a mental template or "skeleton" with slots for details. When you walk into a "birthday party," you don't have to relearn what a chair is. You invoke a "Birthday Frame" that already has slots for cake, presents, and guests. You only need to fill in the specific details (e.g., "The cake is chocolate"). Because the mind is a society, different agents often want different things. One agency might want to "Sleep," while another wants to "Finish this book." Minsky explains that we have "Manager" agents whose only job is to settle disputes between subordinate agents. If the "Sleep" agency is stronger, it suppresses the "Read" agency. Minsky believes that consciousness is a "user illusion"—a simplified story that our higher-level agents tell themselves to keep track of what the millions of lower-level agents are doing.
According to Minsky, we have all these agents in our heads and brains, where each agent is responsible for a tiny simple task, or desires, or goals, whatever it is that motivates it. They come into conflict, and they fight amongst each other, the winner gets to decide what your body does at the moment, and as soon as that need is filled, your brain moves onto deciding what to do next. It sounds like a rather dynamic and complex ecosystem we have in our brains, according to this agent model. According to the model, these “agents” are connected together, in ways we don’t yet understand, all we know is that it’s not three dimensional, not in the way that it does not exist in a 3D space, because we all do, since we are three-dimensional creatures, therefore so do our brains; but in the way that they are interconnected in a way where the inside can be outside, the outside can be the inside, like a mobius strip to an ant, like a tesserect to us.

Since these agents in our brains are connected in ways like a tesseract to us, they communicate with each other in a way that’s a tesseract to us as well. It’s hard to admit, but we know very little about ourselves, especially our bodies, our brains, and the more I’m learning about artificial intelligence, the more I come to realize how little we know of our own intelligence, of our brain, of neuroscience, of psychology, of emotions, pretty much all the most important things that dictate our lives. These agents work together and fight over what the body should do next, the actions that require all of our limbs to agree with each other to accomplish, excluding automatic biochemical reactions that happen regardless if we are aware of it or not. These actions are actions that require a "consciousness" or “awareness” to execute, a medium has to translate agents’ decisions to the body, and that medium is what we call "consciousness".
According to Minsky, consciousness is an illusion. Minsky viewed consciousness as a suitcase word—a term into which we pack many different, unrelated mental activities (like memory, attention, and self-reflection) because we don't understand how they actually work. He believed what we call "consciousness" is actually a system of internal records. When one part of the brain "talks" to another, it uses a simplified summary. We experience that simplified summary as a "thought." We feel like a single entity, but Minsky argued we are a "cloud" of different sub-programs. The feeling of being a "unified I" is just a convenient shorthand our brain uses to keep track of its own state. Minsky was a staunch physicalist. He rejected the idea that consciousness requires some "secret sauce" or quantum mystery. To him, if you build a machine with enough "reflective" layers (agents that monitor other agents), that machine would eventually claim to be conscious for the same reasons we do. This is very scary, but it actually does make sense. ☀️
References & Recommended Reading
I. The Core Theoretical Foundations
These are the primary works that shaped the "Society of Mind" philosophy and the "AI Winter" that preceded NVIDIA's rise.
Minsky, Marvin. The Society of Mind. Simon & Schuster, 1986.
The Inspiration: Jensen Huang’s "bible" for parallel architecture. It argues that intelligence emerges from thousands of simple, mindless agents working together.
Minsky, Marvin, and Seymour Papert. Perceptrons: An Introduction to Computational Geometry. MIT Press, 1969.
The Catalyst: This book famously shut down early neural network research by proving the limitations of single-layer "Perceptrons," leading to the first AI Winter. It set the stage for the hardware breakthroughs we have today.
Rosenblatt, Frank. "The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain." Psychological Review, 1958.
The Origin: The original paper that proposed a machine could "learn" like a brain.
II. First Principles & Cognitive Science
To understand how Jensen thought through these problems, these readings cover the methodology of First Principles and the philosophy of the mind.
Dennett, Daniel C. Consciousness Explained. Little, Brown and Co., 1991.
The Philosophy: Explains the "User Illusion" and the "Intentional Stance," providing the philosophical basis for why a society of simple agents can feel like a single "mind."
Pinker, Steven. How the Mind Works. W. W. Norton & Company, 1997.
The Bridge: Connects evolutionary biology to the computational theory of mind—the idea that the brain is a system of specialized, evolved "gadgets."
Descartes, René. Meditations on First Philosophy. 1641.
The Method: The historical root of "Doubting Everything" to find fundamental truths, which Jensen and Musk have modernized into "First Principles Thinking."
III. The History of the GPU & NVIDIA
For the "hardware" side of the story—how the silicon actually changed to match the philosophy.
Peddie, Jon. The History of the GPU (Series). Springer, 2023.
Vol 1: Steps to Invention
Vol 2: Eras and Environment
Vol 3: From Inception to AI
Why Read: The most comprehensive technical history of how NVIDIA won the graphics war and created the "World's First GPU" (the GeForce 256).
"Jensen Huang on How to Use First-Principles Thinking to Drive Decisions." View From The Top, Stanford Graduate School of Business (Podcast/Transcript), 2024.
The Source: A direct deep-dive from Jensen on his Stanford roots and his "First Principles" framework for running NVIDIA.
IV. Modern Synthesis: Emergence & AI
These works explain the "magic" of emergence that we see in current models like ChatGPT.
Bennett, Max. A Brief History of Intelligence. HarperCollins, 2023.
The Modern View: A fantastic look at how AI and neuroscience have finally converged to prove the "Society of Mind" theories in real-time.
Mitchell, Melanie. Complexity: A Guided Tour. Oxford University Press, 2009.
The Concept: The best entry-point for understanding "Emergence"—how ants, water, and AI models all follow the same rules of collective intelligence.